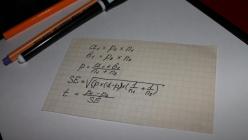В каких случаях вы принимаете научное открытие всерьез? Когда оно «значимо»?
Паранормальные события по определению являются экстраординарными и выходят за рамки мира обычной науки. Если вы делаете ошибочный вывод о том, что результат не случаен, а имеет конкретную причину, то это ошибка I рода. (Ошибочный вывод в том, что реальный неслучайный эффект - всего лишь результат случайности, называется ошибкой II рода.) Говоря проще, ошибка 1 рода - это когда вы считаете, что «происходит что-то необычное», тогда как на самом деле все идет своим чередом. В данном тексте мы рассмотрим процедуру сверки с реальностью, призванную выявлять ошибки I рода.
Пусть ученый проводит эксперимент с целью определить, стоит ли за неким явлением - скажем, необычайной способно стью выигрывать в лотерею, читать мысли или предсказывать результаты выборов - какая-то конкретная причина или это чистая случайность. Пусть далее наш ученый получит подряд несколько позитивных результатов. В конце концов игрок в покер может иногда получить удачные карты, в этом нет ничего таинственного. Да и в лотерею люди иногда выигрывают.
К счастью, существуют статистические процедуры для оценки вероятности ошибки I рода. К примеру, мы считаем, что выигрыши в лотерее распределяются совершенно случайно и честно, так что выигрыш каждого человека зависит исключительно от удачи. При этом некоторым людям все же выпадают выигрыши. Если выигрышей больше, чем можно было ожидать, мы можем заподозрить, что лотерея работает не совсем случайно. Возможно, кто-нибудь жульничает или здесь работают паранормальные силы. Чтобы разобраться в происходящем, статистики вычисляют, сколько выигрышных билетиков должно быть предъявлено, чтобы мы сделали вывод о том, что происходит нечто странное. Может быть, по законам случайности на один миллион участников должно приходиться 10, 100 или даже 1000 выигрышей. Любое число, превышающее 10, 100 или 1000, вызовет подозрения. Но как выбрать допустимое число выигрышей? Все зависит от того, чем вы готовы рискнуть. Насколько вы боитесь совершить ошибку I рода.
«Уровень риска» совершения ошибки I рода называется a-уровнем. Традиционно многие ученые ориентируются на а-уровень 5 % (0,05), но иногда используются и другие уровни (1 % (0,01) и 0,1 % (0,001)). Так, а-уровень 5 % означает, что лотерея становится по-настоящему подозрительной. Если же уровень уверенности не превышает 5 %, т. е. вероятность ошибки не превышает 1/20. Иногда уровень вероятности для краткости называют p-величиной. В научных докладах можно часто встретить следующие утверждения (не забывайте, что при этом р лучше, т. е. меньше, 0,05, и, соответственно, результаты эксперимента значимы):
Мы сравнили уровень успешности предсказания пятидесяти экстрасенсов и пятидесяти людей без заявленных паранормальных способностей. Предсказания экстрасенсов оправдывались в 45 % случаев, предсказания обычных людей - в 41 % случаев.
Предсказания экстрасенсов были точны значительно чаще, чем предсказания обычных людей (р = 0,02). Вывод: результаты эксперимента свидетельствуют о том, что экстрасенсы могут предсказывать будущее.
Если эксперимент не подтвердил точности предсказаний экстрасенсов, отчет может выглядеть примерно так:
Мы сравнили уровень успешности предсказания пятидесяти экстрасенсов и пятидесяти людей без заявленных паранормальных способностей. Предсказания экстрасенсов оправдывались в 44 % случаев, предсказания обычных людей - в 43 % случаев. Превышение успешности предсказаний экстрасенсов по отношению к предсказаниям обычных людей не было статистически значимым (р = 0,12). Вывод: результаты эксперимента не подтверждают вывод о том, что экстрасенсы могут предсказывать будущее.
Обратите внимание: ученые говорят о «статистической значимости» явления, если полученная в ходе эксперимента «-величина не превышает принятого в эксперименте уровня значимости (a-уровня)». Утверждение «Этот результат является статистически значимым, р = 0,02» можно перевести примерно так: «Мы уверены, что этот результат - не просто удача или случайность. Наша статистика показывает, что вероятность ошибки составляет всего 2 шанса из 100, а это лучше, чем уровень 5/100, принятый большинством ученых».
Способ, при помощи которого вычисляется а-уровень для статистических данных, останется за пределами этой книги. Однако заметим, что эта задача может оказаться весьма сложной. К примеру, многократное повторение одного и того же эксперимента может создавать совершенно особую проблему, о которой иногда забывают исследователи паранормального. Любой эксперимент сам по себе напоминает бросание монетки. Со временем при многократном повторении вы можете по чистой случайности получить желаемый результат. В гипотетическом исследовании предсказаний экстрасенсов и обычных людей, о котором мы говорили выше, некоторые участники (как экстрасенсы, так и неэкстрасенсы), вполне воз можно, сделали удачное предсказание случайно. Мы уже объяснили, что статистики умеют оценивать уровень вероятности и учитывать его при обработке результатов. Точно так же, если повторить этот эксперимент сотни раз, исследуя каждый раз по 50 экстрасенсов и неэкстрасенсов, в некоторых случаях доля успешных предсказаний у экстрасенсов обязательно окажется выше - по чистой случайности. Минимум, что вы должны сделать, - это изменить a-уровень так, чтобы учесть возросший риск ложноположительного решения.
Исследователи, которые многократно повторяют один и тот же эксперимент (или учитывают большое количество параметров водном эксперименте), вынуждены принимать дополнительные меры, чтобы исключить ложноположительное решение. Некоторые из них пользуются тестом, придуманным Карло Эмилио Бонферрони (Bonferroni, 1935), и делят а-уровень (0,05 или 0,01) на число экспериментов (или параметров), чтобы скомпенсировать тем самым возросшую вероятность ошибочного результата. Новый a-уровень отражает более жесткие критерии, при помощи которых придется в этом случае оценивать достоверность проведенного исследования. Ведь, если провести аналогию с бросанием костей, вы увеличиваете вероятность выигрыша за счет большого количества бросков. К примеру, если вы провели 100 экспериментов по экстрасенсорному предсказанию будущего (или один эксперимент, в котором попросили участников предсказать поведение 100 отдельных трупп объектов, таких как спортивные матчи, номера лотерейных билетов, природные события и т. д.), то новый a-уровень у вас будет 0,0005 (0,05/100). Таким образом, если после статистической обработки результатов вашего исследования окажется, что уровень достоверности составляет всего 0,05. В данном случае это будет означать, что значимых результатов вам получить не удалось.
Возможно, вы плохо разбираетесь в статистике и с трудом понимаете, о чем идет речь. Тем не менее Бонферрони снабдил нас очень удобным инструментом оценки, пользоваться которым совсем не трудно. При помощи этого инструмента вы всегда можете понять, не возбуждают ли результаты того или иного исследования ложных надежд. Сосчитайте число экспериментов, о которых идет речь. Или число различных «исходящих» переменных, которые подвергались исследованию. Разделите 0,05 на число экспериментов или переменных и получите новое пороговое значение. Уровень достоверности исследования, о котором идет речь, должен быть не выше этого значения (т. е. меньше или равен ему). Только тогда вы можете быть уверены в значимости полученных результатов. Ниже приведен гипотетический отчет об исследовании зеленого чая. Можете ли вы определить, почему он вводит читателя в заблуждение?
Мы проверили действие зеленого чая на успеваемость. В двойном слепом исследовании с применением плацебо, 20 учащихся получали зеленый чай, а еще 20 - подкрашенную воду, похожую на зеленый чай. Участники эксперимента пили чай каждый день в течение месяца. Мы проверяли 5 переменных: средний балл, экзаменационные оценки, оценки за письменные работы, оценки за работу в классе и посещаемость. За письменные работы те, кто пил зеленый чай, получили в среднем «5», а те, кто пил воду, - в среднем «4». Это значимая разница, р = 0,02. Вывод: зеленый чай повышает успеваемость.
А вот тот же отчет с поправкой на тест Бонферрони:
Мы проверили действие зеленого чая на успеваемость. В двойном слепом исследовании с применением плацебо, 20 учащихся получали зеленый чай, а еще 20 - подкрашенную воду, похожую на зеленый чай. Участники эксперимента пили чай каждый день в течение месяца. Мы проверяли 5 переменных: средний балл, экзаменационные оценки, оценки за письменные работы, оценки за работу в классе и посещаемость. Лучше всего зеленый чай сказался на качестве письменных работ. Здесь те, кто пил зеленый чай, получили в среднем «5», а те, кто пил воду, - в среднем «4». Разница в оценках дает нам р = 0,02. Однако этот результат не удовлетворяет а-уровню с поправкой Бонферрони (0,01). Вывод: зеленый чай не повышает успеваемость.
Статистическая значимость результата (p-значение) представляет собой оцененную меру уверенности в его «истинности» (в смысле «репрезентативности выборки»). Выражаясь более технически, p-значение ‑ это показатель, находящийся в убывающей зависимости от надежности результата. Более высокое p-значение соответствует более низкому уровню доверия к найденной в выборке зависимости между переменными. Именно, p-значение представляет собой вероятность ошибки, связанной с распространением наблюдаемого результата на всю популяцию. Например, p-значение=0.05 (т.е. 1/20) показывает, что имеется 5% вероятность, что найденная в выборке связь между переменными является лишь случайной особенностью данной выборки. Иными словами, если данная зависимость в популяции отсутствует, а вы многократно проводили бы подобные эксперименты, то примерно в одном из двадцати повторений эксперимента можно было бы ожидать такой же или более сильной зависимости между переменными.
Во многих исследованиях p-значение=0.05 рассматривается как «приемлемая граница» уровня ошибки.
Не существует никакого способа избежать произвола при принятии решения о том, какой уровень значимости следует действительно считать «значимым». Выбор определенного уровня значимости, выше которого результаты отвергаются как ложные, является достаточно произвольным. На практике окончательное решение обычно зависит от того, был ли результат предсказан априори (т.е. до проведения опыта) или обнаружен апостериорно в результате многих анализов и сравнений, выполненных с множеством данных, а также на традиции, имеющейся в данной области исследований. Обычно во многих областях результат p 0.05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень все еще включает довольно большую вероятность ошибки (5%). Результаты, значимые на уровне p 0.01 обычно рассматриваются как статистически значимые, а результаты с уровнем p 0.005 или p 0.001 как высоко значимые. Однако следует понимать, что данная классификация уровней значимости достаточно произвольна и является всего лишь неформальным соглашением, принятым на основе практического опыта в той или иной области исследования.
Как было уже сказано, величина зависимости и надежность представляют две различные характеристики зависимостей между переменными. Тем не менее, нельзя сказать, что они совершенно независимы. Говоря общим языком, чем больше величина зависимости (связи) между переменными в выборке обычного объема, тем более она надежна.
Если предполагать отсутствие зависимости между соответствующими переменными в популяции, то наиболее вероятно ожидать, что в исследуемой выборке связь между этими переменными также будет отсутствовать. Таким образом, чем более сильная зависимость обнаружена в выборке, тем менее вероятно, что этой зависимости нет в популяции, из которой она извлечена.
Объем выборки влияет на значимость зависимости. Если наблюдений мало, то соответственно имеется мало возможных комбинаций значений этих переменных и таким образом, вероятность случайного обнаружения комбинации значений, показывающих сильную зависимость, относительно велика.
Как вычисляется уровень статистической значимости. Предположим, вы уже вычислили меру зависимости между двумя переменными (как объяснялось выше). Следующий вопрос, стоящий перед вами: «насколько значима эта зависимость?» Например, является ли 40% объясненной дисперсии между двумя переменными достаточным, чтобы считать зависимость значимой? Ответ: «в зависимости от обстоятельств». Именно, значимость зависит в основном от объема выборки. Как уже объяснялось, в очень больших выборках даже очень слабые зависимости между переменными будут значимыми, в то время как в малых выборках даже очень сильные зависимости не являются надежными. Таким образом, для того чтобы определить уровень статистической значимости, вам нужна функция, которая представляла бы зависимость между «величиной» и «значимостью» зависимости между переменными для каждого объема выборки. Данная функция указала бы вам точно «насколько вероятно получить зависимость данной величины (или больше) в выборке данного объема, в предположении, что в популяции такой зависимости нет». Другими словами, эта функция давала бы уровень значимости (p-значение), и, следовательно, вероятность ошибочно отклонить предположение об отсутствии данной зависимости в популяции. Эта «альтернативная» гипотеза (состоящая в том, что нет зависимости в популяции) обычно называется нулевой гипотезой. Было бы идеально, если бы функция, вычисляющая вероятность ошибки, была линейной и имела только различные наклоны для разных объемов выборки. К сожалению, эта функция существенно более сложная и не всегда точно одна и та же. Тем не менее, в большинстве случаев ее форма известна, и ее можно использовать для определения уровней значимости при исследовании выборок заданного размера. Большинство этих функций связано с очень важным классом распределений, называемым нормальным.
Определение показателей значимости через градиент
Нейронная сеть двойственного функционирования может вычислять градиент функции оценки по входным сигналам и обучаемым параметрам сети.
Показателем значимости параметра при решении q- о примера будем называть величину, которая показывает насколько изменится значение функции оценки решения сетью q- о примера если текущее значение параметра w p заменить на выделенное значение w p . Точно эту величину можно определить произведя замену и вычислив оценку сети. Однако учитывая большое число параметров сети вычисление показателей значимости для всех параметров будет занимать много времени. Для ускорения процедуры оценки параметров значимости вместо точных значений используют различные оценки . Рассмотрим простейшую и наиболее используемую линейную оценку показателей значимости. Разложим функцию оценки в ряд Тейлора с точностью до членов первого порядка:
где H 0 q - значение функции оценки решения q- о примера при w =w. Таким образом показатель значимости p- о параметра при решении q- о примера определяется по следующей формуле:
Показатель значимости (1) может вычисляться для различных объектов. Наиболее часто его вычисляют для обучаемых параметров сети. Однако показатель значимости вида (1) применим и для сигналов. Как уже отмечалось в главе сеть при обратном функционировании всегда вычисляет два вектора градиента - градиент функции оценки по обучаемым параметрам сети и по всем сигналам сети. Если показатель значимости вычисляется для выявления наименее значимого нейрона, то следует вычислять показатель значимости выходного сигнала нейрона. Аналогично, в задаче определения наименее значимого входного сигнала нужно вычислять значимость этого сигнала, а не сумму значимостей весов связей, на которые этот сигнал подается.
Усреднение по обучающему множеству
Показатель значимости параметра X q p зависит от точки в пространстве параметров, в которой он вычислен и от примера из обучающего множества. Существует два принципиально разных подхода для получения показателя значимости параметра, не зависящего от примера. При первом подходе считается, что в обучающей выборке заключена полная информация о всех возможных примерах. В этом случае, под показателем значимости понимают величину, которая показывает насколько изменится значение функции оценки по обучающему множеству, если текущее значение параметра w p заменить на выделенное значение w p . Эта величина вычисляется по следующей формуле:
В рамках другого подхода обучающее множество рассматривают как случайную выборку в пространстве входных параметров. В этом случае показателем значимости по всему обучающему множеству будет служить результат некоторого усреднения по обучающей выборке.
Существует множество способов усреднения. Рассмотрим два из них. Если в результате усреднения показатель значимости должен давать среднюю значимость, то такой показатель вычисляется по следующей формуле:
Если в результате усреднения показатель значимости должен давать величину, которую не превосходят показатели значимости по отдельным примерам (значимость этого параметра по отдельному примеру не больше чем О§ p), то такой показатель вычисляется по следующей формуле:
Накопление показателей значимости
Все показатели значимости зависят от точки в пространстве параметров сети, в которой они вычислены, и могут сильно изменяться при переходе от одной точки к другой. Для показателей значимости, вычисленных с использованием градиента эта зависимость еще сильнее, поскольку при обучении по методу наискорейшего спуска (см. раздел ) в двух соседних точках пространства параметров, в которых вычислялся градиент, градиенты ортогональны. Для снятия зависимости от точки пространства используются показатели значимости, вычисленные в нескольких точках. Далее они усредняются по формулам аналогичным (3) и (4). Вопрос о выборе точек в пространстве параметров в которых вычислять показатели значимости обычно решается просто. В ходе нескольких шагов обучения по любому из градиентных методов при каждом вычислении градиента вычисляются и показатели значимости. Число шагов обучения, в ходе которых накапливаются показатели значимости, должно быть не слишком большим, поскольку при большом числе шагов обучения первые вычисленные показатели значимости теряют смысл, особенно при использовании усреднения по формуле (4).
Из анализа литературы и опыта работы группы НейроКомп можно сформулировать следующие задачи, решаемые с помощью контрастирования нейронных сетей.
1. Упрощение архитектуры нейронной сети.
2. Уменьшение числа входных сигналов.
3. Сведение параметров нейронной сети к небольшому набору выделенных значений.
4. Снижение требований к точности входных сигналов.
5. Получение явных знаний из данных.
Алгоритмы контрастирования, рассматриваемые в данной главе, позволяют выделить минимально необходимое множество входных сигналов. Использование минимального набора входных сигналов позволяет более экономично организовать работу нейркомпьютера. Однако у минимального множества есть свои недостатки. Поскольку множество минимально, то информация, несомая одним из сигналов, как правило не подкрепляется другими входными сигналами. Это приводит к тому, что при ошибке в одном входном сигнале сеть ошибается с большой степенью вероятности. При избыточном наборе входных сигналов этого как правило не происходит, поскольку информация каждого сигнала подкрепляется (дублируется) другими сигналами.
Таким образом возникает противоречие - использование исходного избыточного множества сигналов неэкономично, а использование минимального набора сигналов приводит к повышению риска ошибок. В этой ситуации правильным является компромиссное решение - необходимо найти такое минимальное множество, в котором вся информация дублируется. В данном разделе рассматриваются методы построения таких множеств, повышенной надежности. Кроме того, построение дублей второго рода позволяет установить какие из входных сигналов не имеют дублей в исходном множестве сигналов. Попадание такого «уникального» сигнала в минимальное множество является сигналом о том, что при использовании нейронной сети для решения данной задачи следует внимательно следить за правильностью значения этого сигнала.
Существует два типа процедуры контрастирования - контрастирование по значимости параметров и не ухудшающее контрастирование. В данном разделе описаны оба типа процедуры контрастирования.
В данном разделе описан способ определения показателей значимости параметров и сигналов. Далее будем говорить об определении значимости параметров. Показатели значимости сигналов сети определяются по тем же формулам с заменой параметров на сигналы.
Индивида окружает множество находящихся от него на различном расстоянии объектов живой и неживой природы. Если вычесть из их числа те, которые ему неизвестны, а также те, которые ему не нужны, останутся только те, которые нужны, значимые для него.
Значимость (чего-либо) - мера жизненной необходимости (этого) . И мера вероятности затруднения или прекращения жизни в случае отсутствия, дефицита (этого). Объект обретает актуальную значимость, как только он становится предметом какой-либо потребности. Чем важнее потребность, тем выше значимость ее предмета (объекта).
Значимость (объекта процесса, явления) - качество динамичное : сегодня это мне нужно «позарез», а завтра, быть может, не нужно вовсе. Следовательно, важную роль здесь играет фактор времени. Важен и фактор пространства: если нечто, в принципе подходящее для удовлетворения моей потребности, для меня недосягаемо, значимость этого для меня может снижаться.
Субъективность оценки - существенный ее недостаток: так можно упустить нечто важное из свойств оцениваемого объекта, а это, в свою очередь, создает основания для пренебрежения его собственными, внутренними закономерностями.
Значимость имеет индивидуальный и видовой аспекты: совокупность всех значимых для человечества (т.е. человека как вида) объектов много больше, чем совокупность всех значимых для индивида. При этом у животных индивидная значимость чего-либо почти полностью совпадает с видовой, а у человека - нет: в процессе своего развития наш вид сумел реализовать в широкой мере процесс индивидуализации своих представителей.
Итак, значимость это :
- особое качество объекта: объекта обязательно в связи с субъектом потребности, т.е. в плане его пригодности для ее удовлетворения;
- это мера жизненной необходимости (этого). Значимо для живого существа все, посредством чего может быть удовлетворена какая-либо его потребность сейчас или потом;
- значимость динамична, конкретна, имеет общечеловеческий и индивидуальный масштаб.
Виды значимости. Значимость может быть:
- первичной (непосредственной) и вторичной (опосредованной) - пища первично значима, а ложка, вилка, тарелка значимы вторично, только вследствие их связи с приемом пищи.
- условной и безусловной (ситуационной и внеситуационной) -вода для человека (как и любою существа) значима всегда, а некоторые материальные ценности - только при определенных условиях;
- актуальной и потенциальной - (багаж в пути мешает, но по приезде в пункт назначения необходим);
- положительной и отрицательной - все то, что способствует удовлетворению наших потребностей, для нас значимо положительно, а все то, что этому препятствует, значимо отрицательно.
- большой и малой;
- подлинной и мнимой - при увлечении чем-либо мы придаем значимость тем предметам, которые не являются жизненно необходимыми.
Объекты, необходимые в плане удовлетворения потребностей человека, образуют целые значимостные цепочки, где каждое звено оценивается и само по себе, и в свете целого. Важную роль играют изменения, происходящие с самим человеком, и одно из самых главных - в связи с этапами его жизненного пути. Для ребенка значимо одно, для взрослого - другое.
Выгода - мера значимости объекта или способа взаимодействия с ним с точки зрения степени вероятности удовлетворения потребности. Выгода может иметь большое число характеристик как количественных, так и качественных. Одна из ипостасей выгоды - прибыль.
Значимость (чего-либо) индивид находит (определяет) и переживает Способом выявления значимости является оценка, способом проявления уже найденной благодаря оценке значимости является отношение и связанное с ним поведение: по тому, к чему и как человек относится, можно понять, что именно и в какой мере для него значимо. Оценка - это психический механизм нахождения (определения, выявления) значимости, а отношение - способ пребывания (отражения) значимости в психике (сознании) индивида.
Переживание значимости происходит в форме желания: то чего мы в данный момент хотим, то в данный момент для нас и наиболее значимо. Чем интенсивнее нагие желание (чего-либо), тем это значимее для нас. Желание - одна из форм проявления отношения как способа проявления значимости, и оно же, будучи неотъемлемым компонентом иотребностного цикла, отражает процесс ситуационной актуализации и дезактуализации постоянно имеющейся значимости.
В конце нашего сотрудничества мы с Гэри Кляйном все же пришли к согласию, отвечая на основной поставленный вопрос: в каких случаях стоит доверять интуиции эксперта? У нас сложилось мнение, что отличить значимые интуитивные заявления от пустопорожних все же возможно. Это можно сравнить с анализом подлинности предмета искусства (для точного результата лучше начинать его не с осмотра объекта, а с изучения прилагающихся документов). При относительной неизменности контекста и возможности выявить его закономер ности ассоциативный механизм распознает ситуацию и быстро вырабатывает точный прогноз (решение). Если эти условия удовлетворяются, интуиции эксперта можно доверять.
К сожалению, ассоциативная память также порождает субъективно веские, но ложные интуиции. Всякий, кто следил за развитием юного шахматного таланта, знает, что умения приобретаются не сразу и что некоторые ошибки на этом пути делаются при полной уверенности в своей правоте. Оценивая интуицию эксперта, всегда следует проверить, было ли у него достаточно шансов изучить сигналы среды – даже при неизменном контексте.
При менее устойчивом, малодостоверном контексте активируется эвристика суждения. Система 1 может давать скорые ответы на трудные вопросы, подменяя понятия и обеспечивая когерентность там, где ее не должно быть. В результате мы получаем ответ на вопрос, которого не задавали, зато быстрый и достаточно правдоподобный, а потому способный проскочить снисходительный и ленивый ко нтроль Системы 2. Допустим, вы хотите спрогнозировать коммерческий успех компании и считаете, что оцениваете именно это, тогда как на самом деле ваша оценка складывается под впечатлением от энергичности и компетентности руководства фирмы. Подмена происходит автоматически – вы даже не понимаете, откуда берутся суждения, которые принимает и подтверждает ваша Система 2. Если в уме рождается единственное суждение, его бывает невозможно субъективно отличить от значимого суждения, сделанного с профессиональной уверенностью. Вот почему субъективную убежденность нельзя считать показателем точности прогноза: с такой же убежденностью высказываются суждения-ответы на другие вопросы.
Должно быть, вы удивитесь: как же мы с Гэри Кляйном сразу не додумались оценивать экспертную интуицию в зависимости от постоянства среды и опыта обучения эксперта, не оглядываясь на его веру в свои слова? Почему сразу не нашли ответ? Это было бы дельное замечание, ведь решение с самого начала мая чило перед нами. Мы заранее знали, что значимые интуитивные предчувствия командиров пожарных бригад и медицинских сестер отличны от значимых предчувствий биржевых аналитиков и специалистов, чью работу изучал Мил.
Теперь уже трудно воссоздать то, чему мы посвятили годы труда и долгие часы дискуссий, бесконечные обмены черновиками и сотни электронных писем. Несколько раз каждый из нас был готов все бросить. Однако, как всегда случается с успешными проектами, стоило нам понять основной вывод, и он стал казаться очевидным изначально.
Как следует из названия нашей статьи, мы с Кляйном спорили реже, чем ожидали, и почти по всем важным пунктам приняли совместные решения. Тем не менее мы также выяснили, что наши ранние разногласия носили не только интеллектуальный характер. У нас были разные чувства, вкусы и взгляды применительно к одним и тем же вещам, и с годами они на удивление мало изменились. Это наглядно проявляется в том, что каждому из нас ка жется занятным и интересным. Кляйн до сих пор морщится при слове «искажение» и радуется, узнав, что некий алгоритм или формальная методика выдают бредовый результат. Я же склонен видеть в редких ошибках алгоритмов шанс их усовершенствовать. Опять-таки я радуюсь, когда так называемый эксперт изрекает прогнозы в контексте с нулевой достоверностью и получает заслуженную взбучку. Впрочем, для нас в конечном итоге стало важнее интеллектуальное согласие, а не эмоции, нас разделяющие.