$X$. Для начала напомним следующее определение:
Определение 1
Генеральная совокупность -- совокупность случайно отобранных объектов данного вида, над которыми проводят наблюдения с целью получения конкретных значений случайной величины, проводимых в неизменных условиях при изучении одной случайной величины данного вида.
Определение 2
Генеральная дисперсия -- среднее арифметическое квадратов отклонений значений вариант генеральной совокупности от их среднего значения.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда генеральная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае генеральная дисперсия вычисляется по формуле:
С этим понятием также связано понятие генерального среднего квадратического отклонения.
Определение 3
Генеральное среднее квадратическое отклонение
\[{\sigma }_г=\sqrt{D_г}\]
Выборочная дисперсия
Пусть нам дана выборочная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 4
Выборочная совокупность -- часть отобранных объектов из генеральной совокупности.
Определение 5
Выборочная дисперсия -- среднее арифметическое значений вариант выборочной совокупности.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда выборочная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае выборочная дисперсия вычисляется по формуле:
С этим понятием также связано понятие выборочного среднего квадратического отклонения.
Определение 6
Выборочное среднее квадратическое отклонение -- квадратный корень из генеральной дисперсии:
\[{\sigma }_в=\sqrt{D_в}\]
Исправленная дисперсия
Для нахождения исправленной дисперсии $S^2$ необходимо умножить выборочную дисперсию на дробь $\frac{n}{n-1}$, то есть
С этим понятием также связано понятие исправленного среднего квадратического отклонения, которое находится по формуле:
В случае, когда значение вариант не являются дискретными, а представляют из себя интервалы, то в формулах для вычисления генеральной или выборочной дисперсий за значение $x_i$ принимается значение середины интервала, которому принадлежит $x_i.$
Пример задачи на нахождение дисперсии и среднего квадратического отклонения
Пример 1
Выборочная совокупность задана следующей таблицей распределения:
Рисунок 1.
Найдем для нее выборочную дисперсию, выборочное среднее квадратическое отклонение, исправленную дисперсию и исправленное среднее квадратическое отклонение.
Для решения этой задачи для начала сделаем расчетную таблицу:
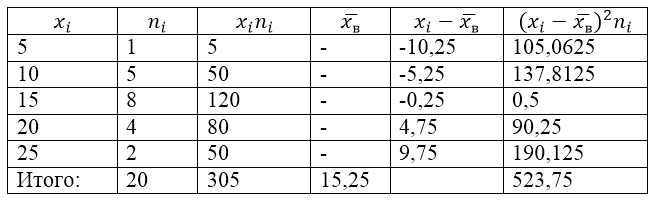
Рисунок 2.
Величина $\overline{x_в}$ (среднее выборочное) в таблице находится по формуле:
\[\overline{x_в}=\frac{\sum\limits^k_{i=1}{x_in_i}}{n}\]
\[\overline{x_в}=\frac{\sum\limits^k_{i=1}{x_in_i}}{n}=\frac{305}{20}=15,25\]
Найдем выборочную дисперсию по формуле:
Выборочное среднее квадратическое отклонение:
\[{\sigma }_в=\sqrt{D_в}\approx 5,12\]
Исправленная дисперсия:
\[{S^2=\frac{n}{n-1}D}_в=\frac{20}{19}\cdot 26,1875\approx 27,57\]
Исправленное среднее квадратическое отклонение.
Приближенный метод оценки колеблемости вариационного ряда - определение лимита и амплитуды, однако не учитывают значений вариант внутри ряда. Основной общепринятой мерой колеблемости количественного признака в пределах вариационного ряда является среднее квадратическое отклонение (σ - сигма) . Чем больше среднее квадратическое отклонение, тем степень колеблемости данного ряда выше.
Методика расчета среднего квадратического отклонения включает следующие этапы:
1. Находят среднюю арифметическую величину (Μ).
2. Определяют отклонения отдельных вариант от средней арифметической (d=V-M). В медицинской статистике отклонения от средней обозначаются как d (deviate). Сумма всех отклонений равняется нулю.
3. Возводят каждое отклонение в квадрат d 2 .
4. Перемножают квадраты отклонений на соответствующие частоты d 2 *p.
5. Находят сумму произведений å(d 2 *p)
6. Вычисляют среднее квадратическое отклонение по формуле:
При n больше 30,или при n меньше либо равно 30, где n - число всех вариант.
Значение среднего квадратичного отклонения:
1. Среднее квадратическое отклонение характеризует разброс вариант относительно средней величины (т.е. колеблемость вариационного ряда). Чем больше сигма, тем степень разнообразия данного ряда выше.
2. Среднее квадратичное отклонение используется для сравнительной оценки степени соответствия средней арифметической величины тому вариационному ряду, для которого она вычислена.
Вариации массовых явлений подчиняются закону нормального распределения. Кривая, отображающая это распределение, имеет вид плавной колоколообразной симметричной кривой (кривая Гаусса). Согласно теории вероятности в явлениях, подчиняющихся закону нормального распределения, между значениями средней арифметической и среднего квадратического отклонения существует строгая математическая зависимость. Теоретическое распределение вариант в однородном вариационном ряду подчиняется правилу трех сигм.
Если в системе прямоугольных координат на оси абсцисс отложить значения количественного признака (варианты), а на оси ординат - частоты встречаемости вариант в вариационном ряду, то по сторонам от средней арифметической равномерно располагаются варианты с большими и меньшими значениями.
Установлено, что при нормальном распределении признака:
68,3% значений вариант находится в пределах М±1s
95,5% значений вариант находится в пределах М±2s
99,7% значений вариант находится в пределах М±3s
3. Среднее квадратическое отлонение позволяет установить значения нормы для клинико-биологических показателей. В медицине интервал М±1s обычно принимается за пределы нормы для изучаемого явления. Отклонение оцениваемой величины от средней арифметической больше, чем на 1s указывает на отклонение изучаемого параметра от нормы.
4. В медицине правило трех сигм применяется в педиатрии для индивидуальной оценки уровня физического развития детей (метод сигмальных отклонений), для разработки стандартов детской одежды
5. Среднее квадратическое отклонение необходимо для характеристики степени разнообразия изучаемого признака и вычисления ошибки средней арифметической величины.
Величина среднего квадратического отклонения обычно используется для сравнения колеблемости однотипных рядов. Если сравниваются два ряда с разными признаками (рост и масса тела, средняя длительность лечения в стационаре и больничная летальность и т.д.), то непосредственное сопоставление размеров сигм невозможно, т.к. среднеквадратическое отклонение - именованная величина, выраженная в абсолютных числах. В этих случаях применяют коэффициент вариации (Cv) , представляющий собой относительную величину: процентное отношение среднего квадратического отклонения к средней арифметической.
Коэффициент вариации вычисляется по формуле:
Чем выше коэффициент вариации, тем большая изменчивость данного ряда. Считают, что коэффициент вариации свыше 30 % свидетельствует о качественной неоднородности совокупности.
Стандартное отклонение является одним из тех статистических терминов в корпоративном мире, которое позволяет поднять авторитет людей, сумевших удачно ввернуть его в ходе беседы или презентации, и оставляет смутное недопонимание тех, кто не знает, что это такое, но стесняется спросить. На самом деле большинство менеджеров не понимают концепцию стандартного отклонения и, если вы один из них, вам пора перестать жить во лжи. В сегодняшней статье я расскажу вам, как эта недооцененная статистическая мера позволит лучше понять данные, с которыми вы работаете.
Что измеряет стандартное отклонение?
Представьте, что вы владелец двух магазинов. И чтобы избежать потерь, важно, чтобы был четкий контроль остатков на складе. В попытке выяснить, кто из менеджеров лучше управляет запасами, вы решили проанализировать стоки последних шести недель. Средняя недельная стоимость стока обоих магазинов примерно одинакова и составляет около 32 условных единиц. На первый взгляд среднее значение стока показывает, что оба менеджера работают одинаково.

Но если внимательнее изучить деятельность второго магазина, можно убедится, что хотя среднее значение корректно, вариабельность стока очень высокая (от 10 до 58 у.е.). Таким образом, можно сделать вывод, что среднее значение не всегда правильно оценивает данные. Вот где на выручку приходит стандартное отклонение.
Стандартное отклонение показывает, как распределены значения относительно среднего в нашей . Другими словами, можно понять на сколько велик разброс величины стока от недели к неделе.
В нашем примере, мы воспользовались функцией Excel СТАНДОТКЛОН, чтобы рассчитать показатель стандартного отклонения вместе со средним.

В случае с первым менеджером, стандартное отклонение составило 2. Это говорит нам о том, что каждое значение в выборке в среднем откланяется на 2 от среднего значения. Хорошо ли это? Давайте рассмотрим вопрос под другим углом – стандартное отклонение равное 0, говорит нам о том, что каждое значение в выборке равно его среднему значению (в нашем случае, 32,2). Так, стандартное отклонение 2 ненамного отличается от 0, и указывает на то, что большинство значений находятся рядом со средним значением. Чем ближе стандартное отклонение к 0, тем надежнее среднее. Более того, стандартное отклонение близкое к 0, говорит о маленькой вариабельности данных. То есть, величина стока со стандартным отклонением 2, указывает на невероятную последовательность первого менеджера.
В случае со вторым магазином, стандартное отклонение составило 18,9. То есть стоимость стока в среднем отклоняется на величину 18,9 от среднего значения от недели к неделе. Сумасшедший разброс! Чем дальше стандартное отклонение от 0, тем менее точно среднее значение. В нашем случае, цифра 18,9 указывает на то, что среднему значению (32,8 у.е. в неделю) просто нельзя доверять. Оно также говорит нам о том, что еженедельная величина стока обладает большой вариабельностью.
Такова концепция стандартного отклонения в двух словах. Хотя оно не дает представление о других важных статистических измерениях (Мода, Медиана…), фактически стандартное отклонение играет решающую роль в большинстве статистических расчетов. Понимание принципов стандартного отклонения прольет свет на суть многих процессов вашей деятельности.
Как рассчитать стандартное отклонение?
Итак, теперь мы знаем, о чем говорит цифра стандартного отклонения. Давайте разберемся, как она считается.
Рассмотрим набор данных от 10 до 70 с шагом 10. Как видите, я уже рассчитал для них значение стандартного отклонения с помощью функции СТАНДОТКЛОН в ячейке H2 (оранжевым).

Ниже описаны шаги, которые предпринимает Excel, чтобы прийти к цифре 21,6.
Обратите внимание, что все расчеты визуализированы, для лучшего понимания. На самом деле в Excel расчет происходит мгновенно, оставляя все шаги за кулисами.
Для начала Excel находит среднее значение выборки. В нашем случае, среднее получилось равным 40, которое на следующем шаге отнимают от каждого значения выборки. Каждую полученную разницу возводят в квадрат и суммируют. У нас получилась сумма равная 2800, которую необходимо разделить на количество элементов выборки минус 1. Так как у нас 7 элементов, получается необходимо 2800 разделить на 6. Из полученного результата находим квадратный корень, это цифра будет стандартным отклонением.

Для тех, кому не совсем ясен принцип расчета стандартного отклонения с помощью визуализации, привожу математическую интерпретацию нахождения данного значения.

Функции расчета стандартного отклонения в Excel
В Excel присутствует несколько разновидностей формул стандартного отклонения. Вам достаточно набрать =СТАНДОТКЛОН и вы сами в этом убедитесь.

Стоит отметить, что функции СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г (первая и вторая функция в списке) дублируют функции СТАНДОТКЛОН и СТАНДОТКЛОНП (пятая и шестая функция в списке), соответственно, которые были оставлены для совместимости с более ранними версиями Excel.
Вообще разница в окончаниях.В и.Г функций указывают на принцип расчета стандартного отклонения выборки или генеральной совокупности. Разницу между двумя этими массивами я уже объяснял в предыдущей .
Особенностью функций СТАНДОТКЛОНА и СТАНДОТКЛОНПА (третья и четвертая функция в списке), является то, что при расчете стандартного отклонения массива в расчет принимаются логические и текстовые значения. Текстовые и истинные логические значения равняются 1, а ложные логические значения равняются 0. Мне трудно представить ситуацию, когда бы мне могли понадобится эти две функции, поэтому, думаю, что их можно игнорировать.
Полученные из опыта величины неизбежно содержат погрешности, обусловленные самыми разнообразными причинами. Среди них следует различать погрешности систематические и случайные. Систематические ошибки обусловливаются причинами, действующими вполне определенным образом, и могут быть всегда устранены или достаточно точно учтены. Случайные ошибки вызываются весьма большим числом отдельных причин, не поддающихся точному учету и действующих в каждом отдельном измерении различным образом. Эти ошибки невозможно совершенно исключить; учесть же их можно только в среднем, для чего необходимо знать законы, которым подчиняются случайные ошибки.
Будем обозначать измеряемую величину через А, а случайную ошибку при измерении х. Так как ошибка х может принимать любые значения, то она является непрерывной случайной величиной, которая вполне характеризуется своим законом распределения.
Наиболее простым и достаточно точно отображающим действительность (в подавляющем большинстве случаев) является так называемый нормальный закон распределения ошибок :
Этот закон распределения может быть получен из различных теоретических предпосылок, в частности, из требования, чтобы наиболее вероятным значением неизвестной величины, для которой непосредственным измерением получен ряд значений с одинаковой степенью точности, являлось среднее арифметическое этих значений. Величина 2 называется дисперсией данного нормального закона.
Среднее арифметическое
Определение дисперсии по опытным данным. Если для какой-либо величины А непосредственным измерением получено n значений a i с одинаковой степенью точности и если ошибки величины А подчинены нормальному закону распределения, то наиболее вероятным значением А будет среднее арифметическое :
a - среднее арифметическое,
a i - измеренное значение на i-м шаге.
Отклонение наблюдаемого значения (для каждого наблюдения) a i величины А от среднего арифметического : a i - a.
Для определения дисперсии нормального закона распределения ошибок в этом случае пользуются формулой:
2 - дисперсия,
a - среднее арифметическое,
n - число измерений параметра,
Среднеквадратическое отклонение
Среднеквадратическое отклонение показывает абсолютное отклонение измеренных значений от среднеарифметического . В соответствии с формулой для меры точности линейной комбинации средняя квадратическая ошибка среднего арифметического определяется по формуле:
![]() , где
, где
a - среднее арифметическое,
n - число измерений параметра,
a i - измеренное значение на i-м шаге.
Коэффициент вариации
Коэффициент вариации характеризует относительную меру отклонения измеренных значений от среднеарифметического :
![]() , где
, где
V - коэффициент вариации,
- среднеквадратическое отклонение,
a - среднее арифметическое.
Чем больше значение коэффициента вариации , тем относительно больший разброс и меньшая выравненность исследуемых значений. Если коэффициент вариации меньше 10%, то изменчивость вариационного ряда принято считать незначительной, от 10% до 20% относится к средней, больше 20% и меньше 33% к значительной и если коэффициент вариации превышает 33%, то это говорит о неоднородности информации и необходимости исключения самых больших и самых маленьких значений.
Среднее линейное отклонение
Один из показателей размаха и интенсивности вариации - среднее линейное отклонение (средний модуль отклонения) от среднего арифметического. Среднее линейное отклонение рассчитывается по формуле:
![]() , где
, где
_
a - среднее линейное отклонение,
a - среднее арифметическое,
n - число измерений параметра,
a i - измеренное значение на i-м шаге.
Для проверки соответствия исследуемых значений закону нормального распределения применяют отношение показателя асимметрии к его ошибке и отношение показателя эксцесса к его ошибке.
Показатель асимметрии
Показатель асимметрии (A) и его ошибка (m a) рассчитывается по следующим формулам:
![]() , где
, где
А - показатель асимметрии,
- среднеквадратическое отклонение,
a - среднее арифметическое,
n - число измерений параметра,
a i - измеренное значение на i-м шаге.
Показатель эксцесса
Показатель эксцесса (E) и его ошибка (m e) рассчитывается по следующим формулам:
![]() , где
, где
При статистической проверке гипотез, при измерении линейной взаимосвязи между случайными величинами.
Среднеквадратическое отклонение:
Стандартное отклонение (оценка среднеквадратического отклонения случайной величины Пол, стены вокруг нас и потолок,x относительно её математического ожидания на основе несмещённой оценки её дисперсии):
где - дисперсия ; - Пол, стены вокруг нас и потолок,i -й элемент выборки; - объём выборки; - среднее арифметическое выборки:
Следует отметить, что обе оценки являются смещёнными. В общем случае несмещённую оценку построить невозможно. Однако оценка на основе оценки несмещённой дисперсии является состоятельной .
Правило трёх сигм
Правило трёх сигм () - практически все значения нормально распределённой случайной величины лежат в интервале . Более строго - не менее чем с 99,7 % достоверностью значение нормально распределенной случайной величины лежит в указанном интервале (при условии, что величина истинная, а не полученная в результате обработки выборки).
Если же истинная величина неизвестна, то следует пользоваться не , а Пол, стены вокруг нас и потолок,s . Таким образом, правило трёх сигм преобразуется в правило трёх Пол, стены вокруг нас и потолок,s .
Интерпретация величины среднеквадратического отклонения
Большое значение среднеквадратического отклонения показывает большой разброс значений в представленном множестве со средней величиной множества; маленькое значение, соответственно, показывает, что значения в множестве сгруппированы вокруг среднего значения.
Например, у нас есть три числовых множества: {0, 0, 14, 14}, {0, 6, 8, 14} и {6, 6, 8, 8}. У всех трёх множеств средние значения равны 7, а среднеквадратические отклонения, соответственно, равны 7, 5 и 1. У последнего множества среднеквадратическое отклонение маленькое, так как значения в множестве сгруппированы вокруг среднего значения; у первого множества самое большое значение среднеквадратического отклонения - значения внутри множества сильно расходятся со средним значением.
В общем смысле среднеквадратическое отклонение можно считать мерой неопределенности. К примеру, в физике среднеквадратическое отклонение используется для определения погрешности серии последовательных измерений какой-либо величины. Это значение очень важно для определения правдоподобности изучаемого явления в сравнении с предсказанным теорией значением: если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратического отклонения), то полученные значения или метод их получения следует перепроверить.
Практическое применение
На практике среднеквадратическое отклонение позволяет определить, насколько значения в множестве могут отличаться от среднего значения.
Климат
Предположим, существуют два города с одинаковой средней максимальной дневной температурой, но один расположен на побережье, а другой внутри континента. Известно, что в городах, расположенных на побережье, множество различных максимальных дневных температур меньше, чем у городов, расположенных внутри континента. Поэтому среднеквадратическое отклонение максимальных дневных температур у прибрежного города будет меньше, чем у второго города, несмотря на то, что среднее значение этой величины у них одинаковое, что на практике означает, что вероятность того, что максимальная температура воздуха каждого конкретного дня в году будет сильнее отличаться от среднего значения, выше у города, расположенного внутри континента.
Спорт
Предположим, что есть несколько футбольных команд, которые оцениваются по некоторому набору параметров, например, количеству забитых и пропущенных голов, голевых моментов и т. п. Наиболее вероятно, что лучшая в этой группе команда будет иметь лучшие значения по большему количеству параметров. Чем меньше у команды среднеквадратическое отклонение по каждому из представленных параметров, тем предсказуемее является результат команды, такие команды являются сбалансированными. С другой стороны, у команды с большим значением среднеквадратического отклонения сложно предсказать результат, что в свою очередь объясняется дисбалансом, например, сильной защитой, но слабым нападением.
Использование среднеквадратического отклонения параметров команды позволяет в той или иной мере предсказать результат матча двух команд, оценивая сильные и слабые стороны команд, а значит, и выбираемых способов борьбы.
Технический анализ
См. также
Литература
| Эта статья предлагается к удалению.
Пояснение причин и соответствующее обсуждение вы можете найти на странице Википедия:К удалению/17 декабря 2012.
|
* Боровиков, В. STATISTICA. Искусство анализа данных на компьютере: Для профессионалов / В. Боровиков. - СПб. : Питер, 2003. - 688 с. - ISBN 5-272-00078-1 .
| Статистические показатели | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Описательная статистика |
|
||||||||||
| Статистический вывод и проверка гипотез |
| ||||||||||


